
Docker et TensorFlow Model Garden pour un tableau de bord.
Un wrapper en intelligence artificielle est un outil ou une bibliothèque qui encapsule des modèles d’apprentissage automatique ou des algorithmes d’IA, facilitant leur utilisation dans diverses applications. Ces wrappers permettent aux développeurs de travailler avec des modèles complexes sans avoir à comprendre tous les détails techniques sous-jacents. La verticalisation fait référence à l’adaptation d’un produit ou d’une technologie pour répondre aux besoins spécifiques d’un secteur particulier. Dans le contexte des wrappers en IA, cela signifie développer des solutions adaptées à des industries comme la santé, la finance, le commerce de détail, etc.
Avantages de la Verticalisation
Spécialisation : Les wrappers verticalisés peuvent offrir des fonctionnalités spécifiques qui répondent mieux aux exigences réglementaires et opérationnelles d’un secteur.
Efficacité : En se concentrant sur un domaine particulier, ces outils peuvent optimiser les performances et réduire le temps de développement.
Adoption : Les entreprises sont plus susceptibles d’adopter des solutions qui répondent directement à leurs besoins sectoriels.
Avenir des Wrappers Verticalisés
L’avenir semble prometteur pour les wrappers verticalisés en raison de l’augmentation continue de l’utilisation de l’IA dans divers secteurs. Avec la montée en puissance du big data et de l’analyse prédictive, les entreprises recherchent des solutions personnalisées qui peuvent être intégrées facilement dans leurs systèmes existants.
L'installation de Docker dépend fortement de votre système d'exploitation. Voici les instructions générales pour les systèmes d'exploitation les plus courants. Veuillez suivre attentivement les étapes correspondant à votre système.
Préparation de la plateforme :
La méthode recommandée pour installer Docker sur Windows est d'utiliser Docker Desktop for Windows.
- Vérifiez les prérequis de votre système:
- Windows 10 ou 11 64-bit Pro, Enterprise ou Education: Hyper-V doit être activé.
- Windows 10 ou 11 64-bit Home: WSL 2 (Windows Subsystem for Linux version 2) est requis. Vous devrez peut-être l'installer et le configurer en premier.
- Téléchargez Docker Desktop for Windows depuis le site officiel de Docker :
https://www.docker.com/products/docker-desktop/ - Double-cliquez sur le fichier
.exetéléchargé pour lancer l'installateur. - Suivez les instructions à l'écran. Vous devrez peut-être accepter les termes de la licence et autoriser l'installation.
- Redémarrez votre ordinateur lorsque l'installateur vous le demande.
- Vérifiez l'installation en ouvrant votre Invite de commandes ou PowerShell et en exécutant
docker --versionetdocker info.
https://docs.docker.com/guides/
.png)
.png)
Le TensorFlow Model Garden est un référentiel avec un certain nombre de mises en œuvre de modèles SOTA (State-of-the-Art) et de solutions de modélisation pour Utilisateurs de TensorFlow. Notre objectif est de démontrer les meilleures pratiques en matière de modélisation afin que Les utilisateurs de TensorFlow peuvent tirer pleinement parti de TensorFlow pour leurs recherches et développement de produits.
Pour améliorer la transparence et la reproductibilité de nos modèles, des journaux d’entraînement sur TensorBoard.dev sont également fournis pour les modèles à la dans la mesure du possible, mais tous les modèles ne conviennent pas.
Utiliser TensorBoard dans les notebooks
TensorBoard peut être utilisé directement dans les expériences d'ordinateurs portables tels que Colab et Jupyter . Cela peut être utile pour partager les résultats, intégrer TensorBoard dans des flux de travail existants et utiliser TensorBoard sans rien installer localement.
Installer
Commencez par installer TF 2.0 et chargez l'extension TensorBoard pour notebook :
Pour les utilisateurs Jupyter: Si vous avez installé Jupyter et TensorBoard dans le même virtualenv, alors vous devriez être bon d'aller. Si vous utilisez une configuration plus compliquée, comme une installation globale Jupyter et noyaux pour différents environnements Conda / virtualenv, vous devez vous assurer que le tensorboard binaire est sur votre PATH dans le contexte de bloc - notes Jupyter. Une façon de le faire est de modifier le kernel_spec préfixer de l'environnement bin répertoire de PATH , comme décrit ici .
Pour les utilisateurs Docker: Si vous utilisez une Docker image de Jupyter serveur portable à l' aide de la nuit tensorflow , il est nécessaire d'exposer non seulement le port de l'ordinateur portable, mais le port du TensorBoard. Ainsi, exécutez le conteneur avec la commande suivante :
docker run -it -p 8888:8888 -p 6006:6006 \
tensorflow/tensorflow:nightly-py3-jupyter
où l' -p 6006 est le port par défaut de TensorBoard. Cela vous allouera un port pour exécuter une instance TensorBoard. Pour avoir des instances concurrentes, il est nécessaire d'allouer plus de ports. En outre, passer --bind_all à %tensorboard pour exposer l'orifice extérieur du récipient.
# Load the TensorBoard notebook extension
%load_ext tensorboard
Importez TensorFlow, datetime et os :
import tensorflow as tf
import datetime, os
Tensor
Télécharger le FashionMNIST ensemble de données et agrandissez:
Créez un modèle très simple :
Entraînez le modèle à l'aide de Keras et du rappel TensorBoard :
Démarrez TensorBoard dans le bloc - notes à l' aide magies :
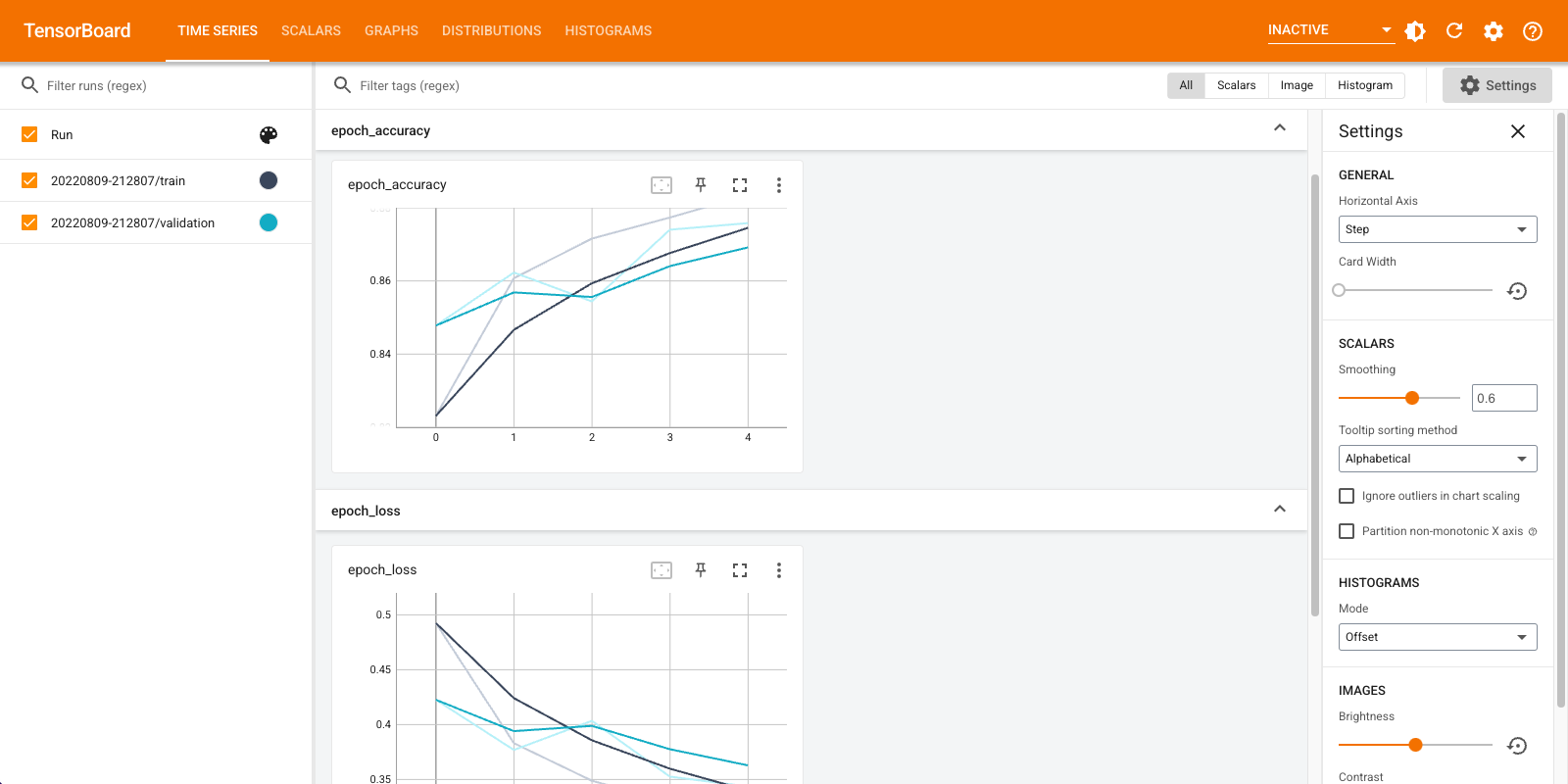
Vous pouvez désormais afficher des tableaux de bord tels que des scalaires, des graphiques, des histogrammes et autres. Certains tableaux de bord ne sont pas encore disponibles dans Colab (comme le plugin de profil).
Le %tensorboard magique a exactement le même format que l'appel de la ligne de commande TensorBoard, mais avec un % --sign devant elle.
Vous pouvez également démarrer TensorBoard avant l'entraînement pour suivre sa progression :

Le même backend TensorBoard est réutilisé en émettant la même commande. Si un autre répertoire de journaux était choisi, une nouvelle instance de TensorBoard serait ouverte. Les ports sont gérés automatiquement.
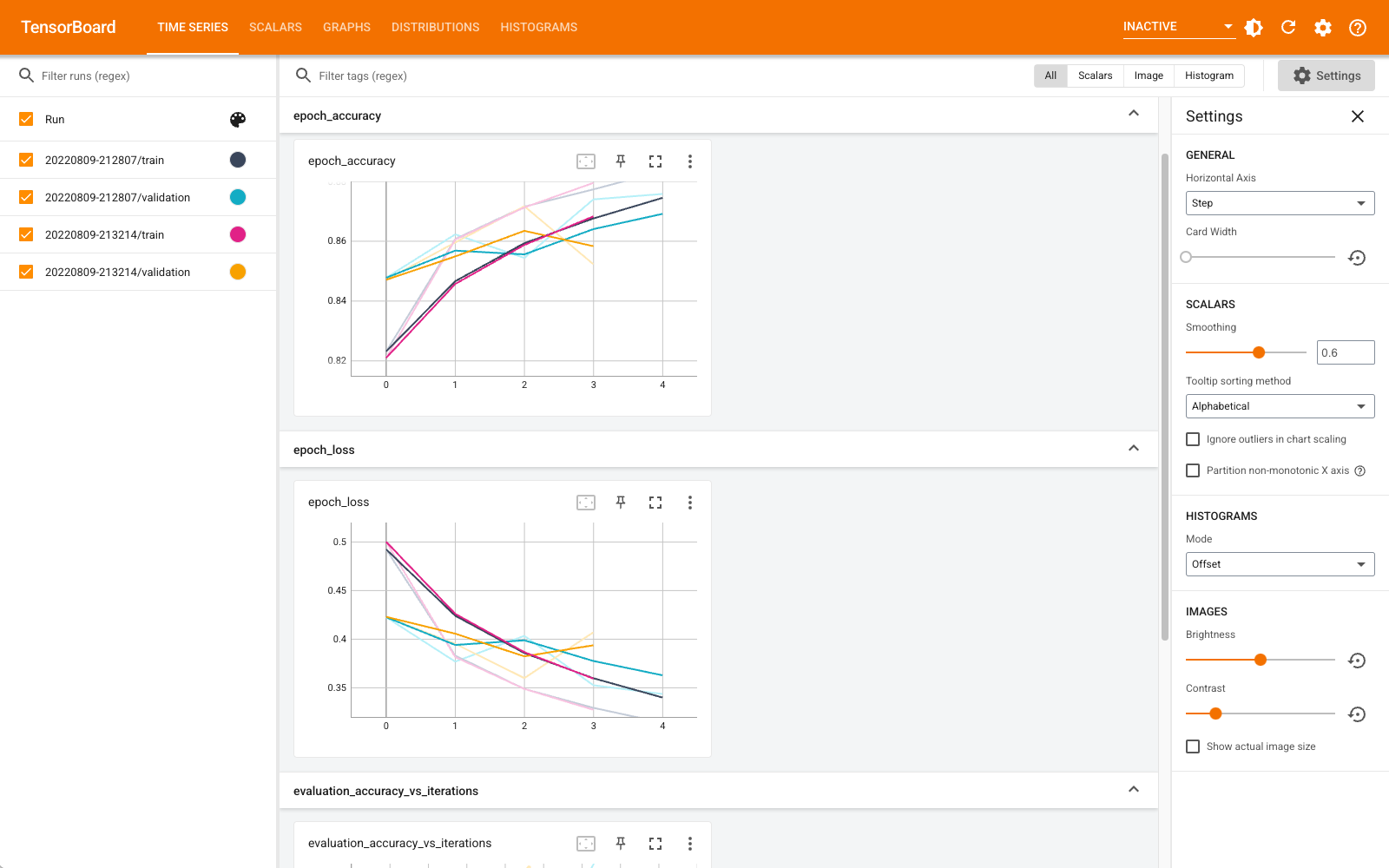
Commencez à entraîner un nouveau modèle et regardez TensorBoard se mettre à jour automatiquement toutes les 30 secondes ou actualisez-le avec le bouton en haut à droite :
Vous pouvez utiliser les tensorboard.notebook API pour un peu plus de contrôle:
Utiliser TensorBoard dans les notebooks | TensorFlow
https://www.tensorflow.org/tensorboard/tensorboard_in_notebooks?hl=fr
https://github.com/tensorflow/models/blob/master/README.md
models/official/README-TPU.md at master · tensorflow/models
https://github.com/tensorflow/models/blob/master/official/README-TPU.md
https://tensorboard.dev/
Modèles et ensembles de données | TensorFlow
https://www.tensorflow.org/resources/models-datasets?hl=fr
Objectif à terme :






Aucun commentaire:
Enregistrer un commentaire